Demande #5812
ferméRégler les soucis de performances de valise
0%
Description
Depuis la mise à jour en Bullseye (décembre 2021), l'ensemble de l'infra Chapril souffre de lenteurs. Mais c'est encore plus flagrant pour valise.
Nous n'avons toujours pas trouvé de solution.
Pour valise, je propose quelques changements qui pourraient améliorer la situation.
- remplacer le cache APCu par redis (cf. Memory caching)
- utiliser redis également pour le file-locking (cf. Using Redis-based transactional file locking)
- faire tourner nextcloud avec php-fpm et apache-mod-fastcgi au lieu de mod-php (pas sûr que ça améliore les perfs, mais isoler les process php des process apache donne plus de marge de manœuvre)
Fichiers
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Mis à jour par pitchum . il y a plus de 2 ans
Comme convenu en réunion ce jour, j'ai déjà gonflé la VM à 4CPU + 4Go de RAM, et désactivé les inscriptions (appli "Registration" désactivée).
Mis à jour par pitchum . il y a plus de 2 ans
- remplacement de mpm_prefox+mod_php par mpm_event+fcgid+php-fpm
- utilisation de redis pour : file-locking et memcache
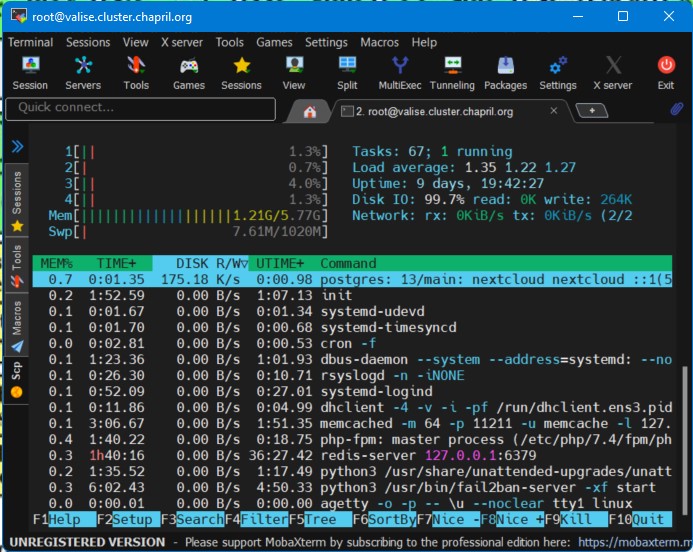
Les perfs sont toujours désastreuses, alors que côté CPU/RAM/Load tout va bien.
Avec apache mod_status on voit que de trop nombreuses requêtes HTTP sont en cours de traitement.
Ça se voit aussi dans les logs apache "/var/log/apache2/valise.chapril.org/valise.chapril.org-access-with-duration.log" + goaccess : le temps de réponse moyen pour /status.php est d'environ 25 secondes.
Côté postgresql, je vois souvent des requêtes 'UPDATE "oc_jobs"' qui durent plus de 30 secondes. Je vais creuser de ce côté-là dès que j'ai un moment.
Mis à jour par pitchum . il y a plus de 2 ans
J'ai fait un peu tuning sur postgresql, avec l'aide de la commande postgresqltuner.pl et le site https://pgtune.leopard.in.ua/
(donc clairement sans vraiment comprendre ce que je faisais hein, donc si quelqu'un veut critiquer ces modifs, je suis preneur :) )
Ces modifications se trouvent dans /var/lib/postgresql/13/main/postgresql.auto.conf (ça aurait pu se faire dans /etc/postgresql/13/main/postgresql.conf mais j'aime bien l'idée de séparer nos customisations)
max_connections = 100 shared_buffers = 768MB effective_cache_size = 2304MB maintenance_work_mem = 192MB checkpoint_completion_target = 0.9 wal_buffers = 16MB default_statistics_target = 100 random_page_cost = 4 effective_io_concurrency = 2 work_mem = 3932kB min_wal_size = 1GB max_wal_size = 4GB max_worker_processes = 4 max_parallel_workers_per_gather = 2 max_parallel_workers = 4 max_parallel_maintenance_workers = 2 checkpoint_completion_target = 0.8 log_min_duration_statement = 4000 shared_preload_libraries = 'pg_stat_statements'
Valise est redevenu à peu près utilisable ce soir, mais je n'ai aucune idée de pourquoi, car aucun des changements que j'ai pu faire aujourd'hui n'ont eu d'effet visible immédiatement.
Mis à jour par pitchum . il y a plus de 2 ans
Quelques tests de latence disque sur valise, sur 2 partitions appartenant à 2 fichiers qcow2 distincts. C'est moins pire que les résultats sur d'autres VM.
=(^-^)=root@valise:/etc# export TEST_FILE=/var/testfile_dd_latency ; dd if=/dev/zero of=${TEST_FILE} bs=512 count=1000 oflag=dsync ; rm -f ${TEST_FILE} ; unset TEST_FILE
1000+0 enregistrements lus
1000+0 enregistrements écrits
512000 octets (512 kB, 500 KiB) copiés, 587,265 s, 0,9 kB/s
=(^-^)=root@valise:/etc# export TEST_FILE=/var/www/valise.chapril.org/data/testfile_dd_latency ; dd if=/dev/zero of=${TEST_FILE} bs=512 count=1000 oflag=dsync ; rm -f ${TEST_FILE} ; unset TEST_FILE
1000+0 enregistrements lus
1000+0 enregistrements écrits
512000 octets (512 kB, 500 KiB) copiés, 194,451 s, 2,6 kB/s
Mis à jour par pitchum . il y a plus de 2 ans
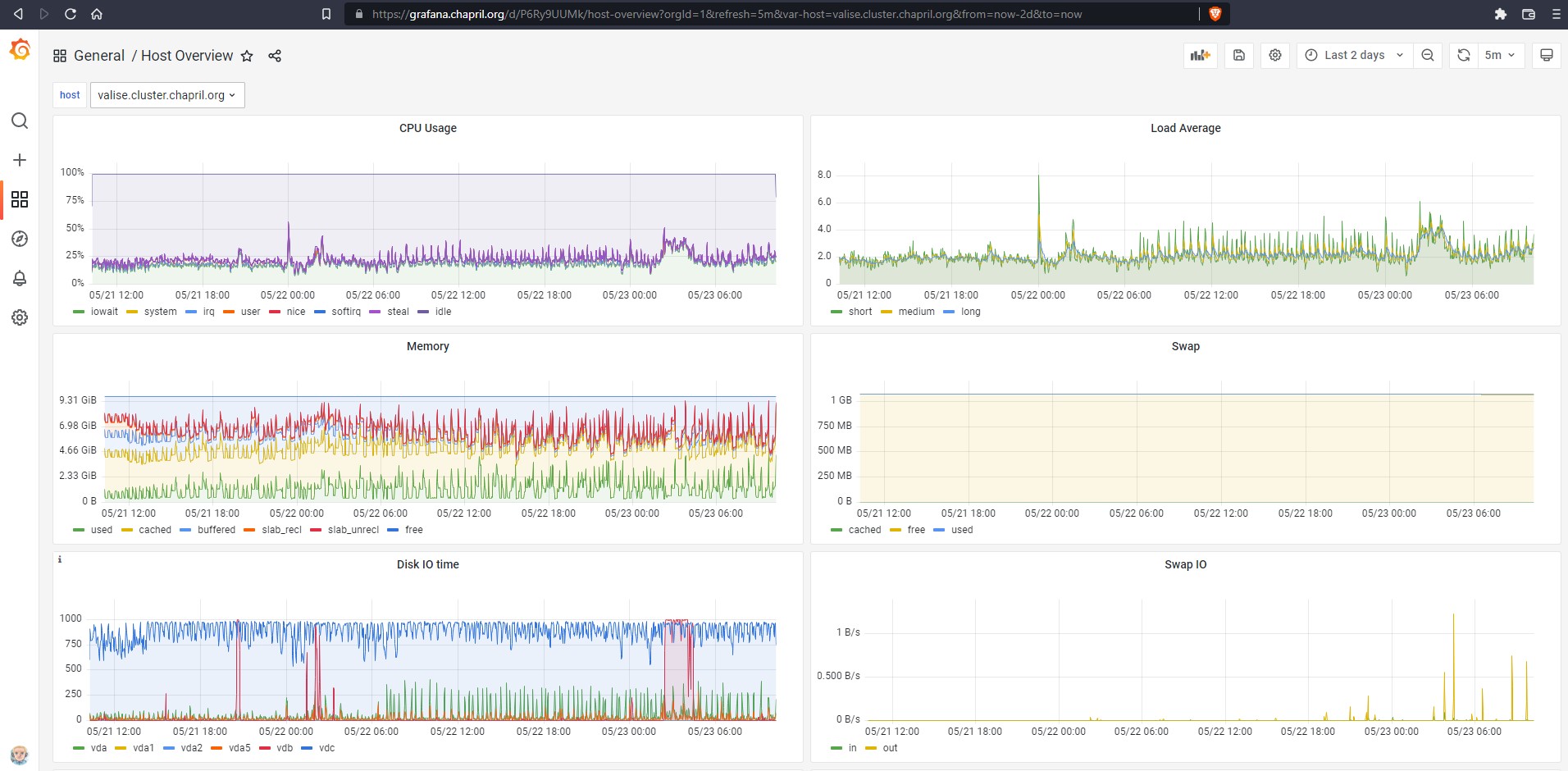
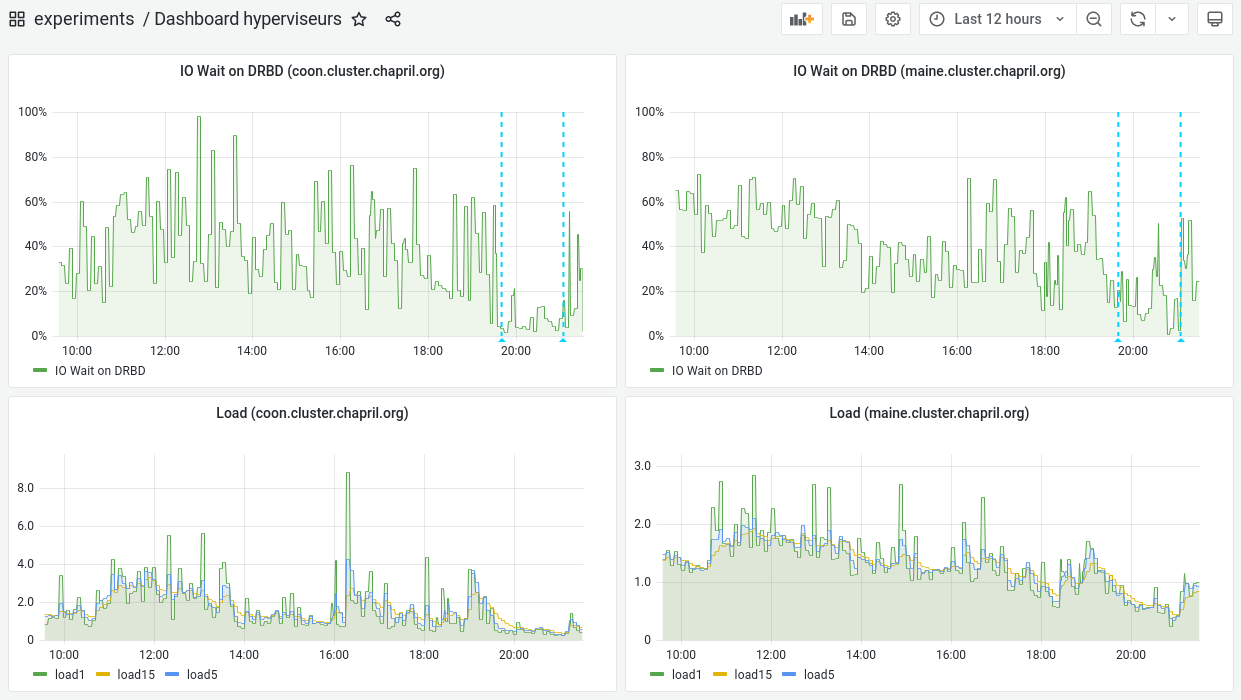
- Fichier iowait_load_hyperviseurs.png iowait_load_hyperviseurs.png ajouté
Après avoir coupé la VM valise (qui tournait sur maine) pendant un peu plus d'une heure, on voit assez l'impact positif sur l'IOWait de coon.
Mis à jour par Chris Mann il y a plus de 2 ans
https://pad.chapril.org/p/2SeafileOrNot2Seafile
Je me demandais si NextCloud était convenable à des grandes installations et si Seafile avait un apport particulier.
Au regard de cette page pour déployer Seafile dans un cluster, je suis tout de suite impressionné par le fait que Seafile aurait été prévu pour un déploiement massif.
https://manual.seafile.com/deploy_pro/deploy_in_a_cluster/
En contraste, il n'y a pas de documentation pour le déploiement de Next Cloud en cluster. Au contraire, il y a simplement des bricolages avec Kubernetes ou Docker.
https://help.nextcloud.com/t/how-cluster-nextcloud-18/81416
https://faun.pub/nextcloud-scale-out-using-kubernetes-93c9cac9e493
https://greg.jeanmart.me/2020/04/13/deploy-nextcloud-on-kuberbetes--the-self-hos/
https://severalnines.com/database-blog/deploying-highly-available-nextcloud-mysql-galera-cluster-and-glusterfs
En tant qu'architecte, si un logiciel n'est pas conçu pour aller à l'échelle, il faut pas s'attendre à ce que ce soit le cas.
Serait-il possible de migrer de NextCloud vers Seafile ?
Mis à jour par Chris Mann il y a plus de 2 ans
Le plus que je regarde, le plus qu'il me semble que la réponse à question de comment faire marcher Next Cloud à l'échelle est de contracter un support de Next Cloud. Il vaudrait peut-être la peine de contacter l'éditeur.
Par contre, Own Cloud semble fournir des informations utiles pour le sujet de dimensionnement:
Notamment, la configuration demande plus de RAM que nous n'avons allouée (16 Go minimum). Plus bas, il y a des recommandations pour des installations plus grandes.
Mis à jour par Chris Mann il y a plus de 2 ans
Peut-être deactiver le swap et augment le RAM.
La nature de l'appli est intense en RAM et mettra la pagaille en I/O si le swap est utilisé de manière excessive.
Mis à jour par pitchum . il y a plus de 2 ans
De mon côté, j'expérimente depuis ce matin le fait que la VM valise n'utilise plus DRBD.
Pour ça, j'ai migré, à chaud, les données des disques qcow2 vers de nouveaux disques LVM. En m'inspirant de ce que j'avais fait dans le ticket #5763.
Sur maine¶
Créer 2 nouveaux disques LVM :
lvcreate -n vm-valise-sys -L 20G vg_maine lvcreate -n vm-valise-data -L 500G vg_maine
Brancher ces disques sur la VM valise, à chaud :
virsh attach-disk valise /dev/vg_maine/vm-valise-sys vdc --subdriver raw --live --config virsh attach-disk valise /dev/vg_maine/vm-valise-data vdd --subdriver raw --live --config
Sur valise¶
Constater que les disques sont apparus :
=(^-^)=root@valise:~# dmesg -T | egrep ' vd[cd]' | tail [dim. avril 10 08:07:02 2022] vdc: detected capacity change from 0 to 21474836480 [dim. avril 10 08:07:10 2022] vdd: detected capacity change from 0 to 322122547200
Créer un PV avec chacun des nouveaux disques :
pvcreate /dev/vdc pvcreate /dev/vdd
Fusionner chaque nouveau PV au VG existant kivabien© :
vgextend modele-vg /dev/vdc vgextend valise-vg-data /dev/vdd
Déplacer les données des anciens PV (basés sur qcow2+drbd) vers les nouveaux PV (basés sur LVM) :
pvmove /dev/vda1 /dev/vdc # rapide pvmove /dev/vda5 /dev/vdc # un peu long pvmove /dev/vdb /dev/vdd # encore plus long
Et maintenant, attendre... Et surveiller la métrologie et la supervision.
Mis à jour par pitchum . il y a plus de 2 ans
Chris Mann a écrit :
Serait-il possible de migrer de NextCloud vers Seafile ?
Je dirais que non. Il vaudrait mieux envisager de ne plus accepter de nouveaux comptes sur Valise (ce qui est déjà le cas actuellement), et éventuellement mettre en place un Seafile à côté, puis encourager les gens à y migrer leurs contenus s'ils le souhaitent.
Valise a déjà plus de 1500 comptes. Faire changer les habitudes de 1500 personnes c'est pas anodin. Et il vaudrait mieux éviter de faire ça de façon brutale.
Chris Mann a écrit :
Notamment, la configuration demande plus de RAM que nous n'avons allouée (16 Go minimum).
Ajouter de la RAM devrait améliorer les performances, ne serait-ce que parce que le noyau peu l'utiliser pour son buffer/cache, et ainsi limiter les accès disque.
Mais 16Go ça représente la moitié de la RAM totale disponible sur nos hyperviseurs... Donc ce sera pas pour tout de suite.
Mis à jour par Pierre-Louis Bonicoli il y a plus de 2 ans
pitchum . a écrit :
Chris Mann a écrit :
Serait-il possible de migrer de NextCloud vers Seafile ?
Je dirais que non. Il vaudrait mieux envisager de ne plus accepter de nouveaux comptes sur Valise (ce qui est déjà le cas actuellement), et éventuellement mettre en place un Seafile à côté, puis encourager les gens à y migrer leurs contenus s'ils le souhaitent.
Valise a déjà plus de 1500 comptes. Faire changer les habitudes de 1500 personnes c'est pas anodin. Et il vaudrait mieux éviter de faire ça de façon brutale.Chris Mann a écrit :
Notamment, la configuration demande plus de RAM que nous n'avons allouée (16 Go minimum).
Ajouter de la RAM devrait améliorer les performances, ne serait-ce que parce que le noyau peu l'utiliser pour son buffer/cache, et ainsi limiter les accès disque.
Mais 16Go ça représente la moitié de la RAM totale disponible sur nos hyperviseurs... Donc ce sera pas pour tout de suite.
Si le résultat de l'analyse du problème est que ce service requiert plus de ressources matérielles que celles disponibles, Fred a rappelé qu'il était tout à fait envisageable d'y allouer plus de ressources. Mais il est bien nécessaire d'effectuer l'analyse du problème pour déterminer comment utiliser ces ressources supplémentaires: renouveler les hyperviseurs actuels, ajouter un hyperviseur dédié au service valise, déplacer les SGDB dans des VM dédiées ...
Pitchum: une suggestion de test: lancer la VM en bloquant les accès réseaux (par exemple via netfilter) afin de déterminer si les ressources matérielles utilisées par le service dépendent de l'activité des utilisateurs ou non.
Mis à jour par Chris Mann il y a plus de 2 ans
A la lecture de
J'étais en en train d'essayer d'évaluer l'impacte de chaque service. Et POOF, il est allé où Redis? PAFm Disparu!
=(^-^)=root@valise:~# systemctl status redis
● redis-server.service - Advanced key-value store
Loaded: loaded (/lib/systemd/system/redis-server.service; enabled; vendor preset: enabled)
Active: inactive (dead) since Sun 2022-04-10 12:17:29 CEST; 1h 59min ago
Docs: http://redis.io/documentation,
man:redis-server(1)
Process: 680943 ExecStart=/usr/bin/redis-server /etc/redis/redis.conf --supervised systemd --daemonize no (code=exited, status=0/SUCCESS)
Main PID: 680943 (code=exited, status=0/SUCCESS)
Status: "Saving the final RDB snapshot"
CPU: 11min 27.152s
avril 09 10:31:31 valise.cluster.chapril.org systemd[1]: Stopped Advanced key-value store.
avril 09 10:31:31 valise.cluster.chapril.org systemd[1]: redis-server.service: Consumed 27min 43.843s CPU time.
avril 09 10:31:31 valise.cluster.chapril.org systemd[1]: Starting Advanced key-value store...
avril 09 10:31:31 valise.cluster.chapril.org systemd[1]: Started Advanced key-value store.
avril 10 12:17:17 valise.cluster.chapril.org systemd[1]: Stopping Advanced key-value store...
avril 10 12:17:29 valise.cluster.chapril.org systemd[1]: redis-server.service: Succeeded.
avril 10 12:17:29 valise.cluster.chapril.org systemd[1]: Stopped Advanced key-value store.
avril 10 12:17:29 valise.cluster.chapril.org systemd[1]: redis-server.service: Consumed 11min 27.152s CPU time.
=(^-^)=root@valise:~# redis-cli ping
Could not connect to Redis at 127.0.0.1:6379: Connection refused
No more Redis ?
OwnCloud semble suggérer une séparation des services / serveurs. Je pense que c'est pour la redondance.
A part Redis, nagios / icinga2 prend des resources importante au fait. (suivi de fail2ban0server).
Mis à jour par pitchum . il y a plus de 2 ans
Chris Mann a écrit :
J'étais en en train d'essayer d'évaluer l'impacte de chaque service. Et POOF, il est allé où Redis? PAFm Disparu!
[...]
No more Redis ?
Pas de panique, c'est moi qui avait coupé les services (redis, postgres, php-fpm, ...) et mis en maintenance valise pendant le pvmove qui s'éternisait.
Tout est maintenant relancé et valise tourne correctement, pour l'instant.
Mis à jour par Chris Mann il y a plus de 2 ans
Je me demande si Redis peut être une piste d’amélioration.
https://redis.io/docs/reference/optimization/latency/
Si on prenait une machine lambda chez Hetzner dans le même data-center (ou proche), on pourrait externaliser Redis. Un serveur CX21 avec 4 Go ferait l'affaire pour 5,83 € HT je suppose par mois. Sinon le CX31 ...
On pourrait faire de même avec PostgreSQL, mais REDIS me semble le plus simple.
REDIS en mémoire sur SWAP m’interroge.
Mis à jour par Chris Mann il y a plus de 2 ans
On dirait que le serveur est fonctionnel de nouveau. Pourrions-nous passer de "panne majeure" à "lenteurs occasionnelles" sur status.chapril.org ?
Mis à jour par Pierre-Louis Bonicoli il y a plus de 2 ans
- Fichier valise-ram.png valise-ram.png ajouté
- Fichier valise-php-fpm.png valise-php-fpm.png ajouté
- Fichier valise-connexion-bastion.png valise-connexion-bastion.png ajouté
La mémoire allouée à la machine a été augmentée le 23/04: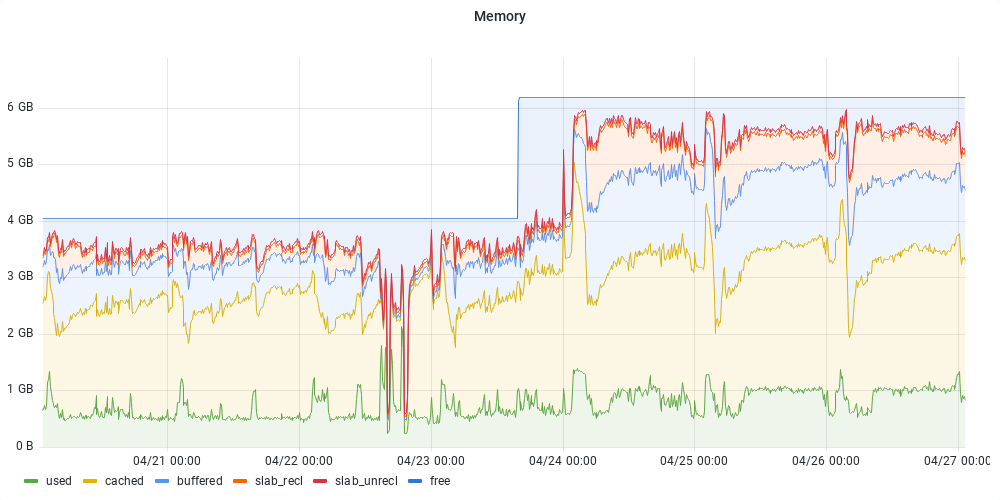
Le plafond du nombre de processus php-fpm est régulièrement atteint depuis 3 jours: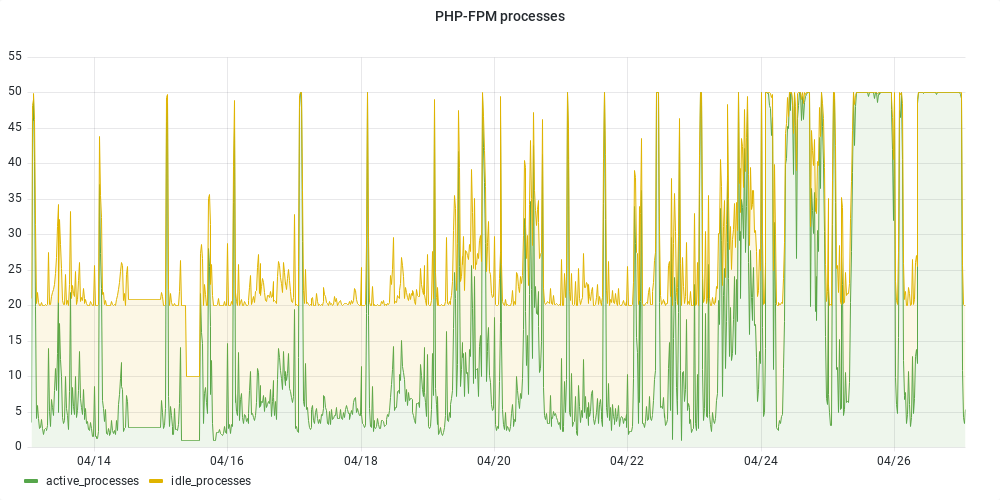
Les connexions depuis le bastion sont plus importantes depuis 2 jours: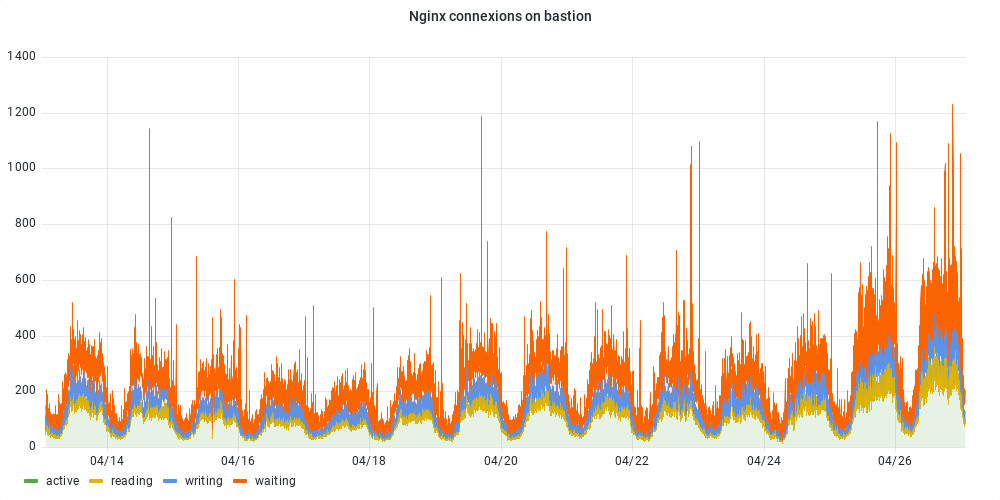
Les graphes d'utilisation du CPU et load ne présentent pas les mêmes variations que celles des deux graphes précédents.
Mis à jour par pitchum . il y a plus de 2 ans
Pierre-Louis Bonicoli a écrit :
La mémoire allouée à la machine a été augmentée le 23/04:
Oui, c'est moi qui ai ajouté 2Go de RAM.
Mais ça n'a pas vraiment eu d'effet positif notable. Au contraire, ça pousse probablement l'hyperviseur (maine) à swapper plus. Donc je viens de réduire à nouveau la RAM allouée à valise à 4Go, en attendant l'ajout de RAM sur les hyperviseurs vendredi.
Mis à jour par Chris Mann il y a plus de 2 ans
Voici les préconisations OwnCloud pour 150 â 1000 utilisateurs (nous 1500)
Components
2 to 4 application servers with four sockets and 32GB RAM.
2 DB servers with four sockets and 64GB RAM.
1 HAproxy load balancer with two sockets and 16GB RAM.
NFS storage server as needed.
Mis à jour par Pierre-Louis Bonicoli il y a plus de 2 ans
Des problèmes sont rencontrés aujourd'hui, Didier indique que le service est à nouveau en panne.
Un nouveau test est lancé: le blocage des accès utilisateurs au service valise pendant une heure tout en laissant la VM et le service tourner. Cela devrait permettre de déterminer si les problèmes sont liés à des actions utilisateurs ou non. Le blocage est fait à partir du bastion- en décommentant les deux lignes
include /etc/nginx/maintenance;dans/etc/nginx/sites-available/valise.chapril.org - puis en exécutant
systemctl reload nginx.servicepour prendre en compte ces modifications.
Après cela il n'y a plus de connexion vers depuis le bastion vers la VM valise (testé avec ss --numeric --tcp --process dst 192.168.1.222). Depuis mon laptop la page Maintenance en cours est bien affichée lorsque j'accède à https://valise.chapril.org.
Mis à jour par Chris Mann il y a plus de 2 ans
Suite à une séance de travail @Pierre-Louis Bonicoli et @Chris Mann
1. Nous ne saurions pas exactement quelle est la source du problème dont les écritures disques et potentiellement le load
- I/O 100 à 200% temps d'attente HTOP lors de non-utilisation du serveur
- I/O postgresql et collectd en io les plus important tjs en non-utilisateur du serveur
2. L'éditeur préconiserait une infra de trois types de machines physiques et trois services pour une base de 150 à 1000 utilisateurs (nous sommes à 1500)
- serveur d'applications de 32 Go,
- de base de données de 64 Go,
- serveur proxy ou utilitaire de 16 Go (j'imagine aussi pour le REDIS, le LDAP et le NFS, bien que ces services peuvent être externes)
3. Notre serveur sur Hetzner est EX41,
- soit avec deux disques SATA (ou SATA-2 ou SATA-3)
- avec des infos SMART inconnues
4. Option de prendre un hyperviseur « High I/O » (responsabilité de préconisation n'engage que @Chris Mann)
- Prendre https://www.hetzner.com/dedicated-rootserver/matrix-ax en mode NVMe
- Soit mettre le VM completement sur un hyperviseur sur cette machine
- Soit mettre juste la base de données sur cette machine
Raisonnement: Les I/O améliorés nous permettent du temps avant d'avoir un serveur PostgreSQL optimisé pour le PostgreSQL
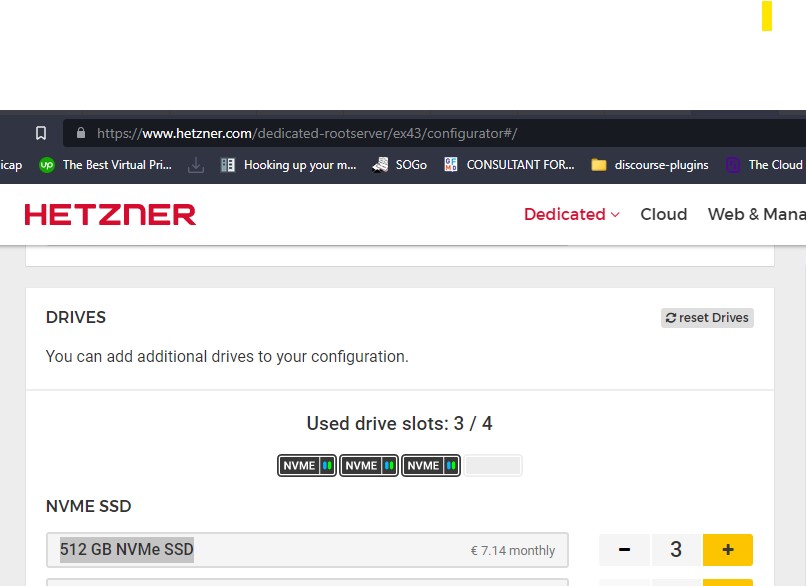
5. Option d'ajout de disque SSD ou NVMe SSD sur EX41 existant
- Prendre un disque 512Go pour le EX41 existant (image ci-contre pour le EX43)
Voir option 4.
6. Option d'éteindre collectd
Collectd semble prendre des ressources importantes en I/O. on pourrait vivre sans les informations qu'elle remonte.
7. Mieux prendre en main l'outil
Aller, c'est pour moi, ... un peu de courage à moi
Mis à jour par Chris Mann il y a plus de 2 ans
- Fichier htp-valise-services-eteints.jpg ajouté
- Fichier htp-valise-services-eteints.jpg htp-valise-services-eteints.jpg ajouté
Ci-joint deux fichiers joints par rapport aux options ci-dessus.
Avec un accès à un disque directement depuis valise, je migre le dossier de stockage et rallume le service (en éteignant collectd).
Mis à jour par Chris Mann il y a plus de 2 ans
- Fichier hetzner-ex43-ajout-nvme-ssd.jpg hetzner-ex43-ajout-nvme-ssd.jpg ajouté
Voici le bon fichier pour l'ajout d'un disque sur la machine hyperviseur.
Mis à jour par Pierre-Louis Bonicoli il y a plus de 2 ans
Pitchum, Chris et moi-même avons échangé à propos de ces problèmes, voici les notes de cet échange:
- Il n'y a pas de limitation au niveau de la bande passante des hyperviseurs
- Une fois les accès utilisateurs bloqués au niveau du bastion, le load moyen plafonne à 1. Désactiver les tâches cron nextcloud sur valise permet alors d'atteindre un load plus faible.
- le problème ne semble pas venir de l'utilisation de DRBD
- le problème ne semble pas venir du transfert des fichiers entre les clients et le serveur mais du service PostgreSQL
- Suite à l'ajout de mémoire sur les hyperviseurs, allouer plus de RAM à la machine virtuelle valise. Il sera ensuite nécessaire d'adapter la configuration PostgreSQL en fonction.
- revenir avec
/varsur drbd (un disque LVM sur l'hyperviseur est actuellement utilisé).
- l'utilisation relativement importantes des ressources CPU par les tâches CRON NextCloud.
- vérifier qu'il n'y a pas une utilisation inattendue du service (par exemple un utilisateur avec un très très grand nombre de petits fichiers)
- ajout de disques dédiés (rapides) pour le service PostgreSQL au niveau des hyperviseurs
- amélioration de l'architecture de PostgreSQL
- ✅ repasser à warning pour le loglevel des logs
- ✅ désactiver la redirection sur le bastion
- ✅ mettre à jour cachet
- ✅ réactiver les taches cron nextcloud sur valise (
/etc/cron.d/valisechaprilorg)
Mis à jour par Pierre-Louis Bonicoli il y a plus de 2 ans
- le niveau de verbosité a été augmenté
- les accès utilisateurs étaient bloqués
- les tâches cron nextcloud étaient exécutées toutes les 15 minutes
Première analyse des taches cron exécutées entre le 2022-05-17 23h (UTC+2) et le 2022-05-18 4h39 (UTC+2), soit environ 5h30:
# jq 'select(.app == "cron")|.time' nextcloud-debug_enabled.2022-05-18.log | head -n1 "2022-05-17T21:00:02+00:00" # jq 'select(.app == "cron")|.time' nextcloud-debug_enabled.2022-05-18.log | tail -n1 "2022-05-18T02:39:12+00:00"
On compte le temps passé par type de tâche (une tâche peut être instanciée plusieurs fois avec des paramètres différents):
# jq 'select(.app == "cron").message' nextcloud-debug_enabled.2022-05-18.log | grep -m 1 Finished
"Finished OCA\\AdminAudit\\BackgroundJobs\\Rotate job with ID 26 in 0 seconds"
# jq 'select(.app == "cron").message' nextcloud-debug_enabled.2022-05-18.log | awk ' /Finished/ {spent[$2]+=$8} END { for (i in spent) {print spent[i] " " i}}' | sort -n | tail -n 5
43 OCA\\UpdateNotification\\Notification\\BackgroundJob
64 OCA\\DAV\\BackgroundJob\\EventReminderJob
104 OCA\\ServerInfo\\Jobs\\UpdateStorageStats
351 OCA\\Passwords\\Cron\\CheckPasswordsJob
46564 OCA\\DAV\\BackgroundJob\\RefreshWebcalJob
Le temps passé (1ère colonne) par identifiant d'instance de tâche (chaque instance à un identifiant constant)
# jq 'select(.app == "cron").message' nextcloud-debug_enabled.2022-05-18.log | awk ' /Finished/ {spent[$2 " " $6]+=$8} END { for (i in spent) {print spent[i] ":" i}}' | sort -n | tail -n 5
1721: OCA\\DAV\\BackgroundJob\\RefreshWebcalJob 326894
5357: OCA\\DAV\\BackgroundJob\\RefreshWebcalJob 209234
9263: OCA\\DAV\\BackgroundJob\\RefreshWebcalJob 231115
12541: OCA\\DAV\\BackgroundJob\\RefreshWebcalJob 157918
13141: OCA\\DAV\\BackgroundJob\\RefreshWebcalJob 195496
On vérifie le temps passé tel qu'il est stocké dans la base (au moment de la rédaction de ce commentaire):
- par type de tâche:
# SELECT sum(execution_duration), class from oc_jobs group by class order by sum desc limit 4; sum | class -------+--------------------------------------------------- 22737 | OCA\DAV\BackgroundJob\RefreshWebcalJob 351 | OCA\Passwords\Cron\CheckPasswordsJob 43 | OCA\UpdateNotification\Notification\BackgroundJob 39 | OCA\Activity\BackgroundJob\ExpireActivities - par instance de tâche:
nextcloud=# SELECT sum(execution_duration), class, id from oc_jobs group by id order by sum desc limit 4; sum | class | id -------+----------------------------------------+-------- 13141 | OCA\DAV\BackgroundJob\RefreshWebcalJob | 195496 1721 | OCA\DAV\BackgroundJob\RefreshWebcalJob | 326894 1471 | OCA\DAV\BackgroundJob\RefreshWebcalJob | 251542 886 | OCA\DAV\BackgroundJob\RefreshWebcalJob | 310256
Les requêtes SQL sont exécutées de manière désynchronisées (dans le futur) par rapport aux manipulation sur le fichier de log qui lui est figé, une partie des durées d'exécution sont cohérentes.
Il y a donc des tâches qui sont exécutées sur une grande partie (13141 secondes, environ 3h40) de la durée pendant laquelle le niveau de verbosité des logs était augmenté. Il n'y a pas d'erreur dans les logs qui explique cette durée d'exécution importante.
Il est possible que le type de tâche OCA\DAV\BackgroundJob\RefreshWebcalJob soit responsable des requêtes SQL mais cette analyse ne le démontre pas.
En lien avec l'analyse du comportement des tâches cron nextcloud: je propose de bloquer à nouveau l'accès au service pendant une durée limitée tout en vérifiant plus précisément l'activité de la base de données (via une configuration/méthode/outil à identifier: après activation de track_io_timing ? via des requêtes directement sur la base ou pgstats, pg_activity, powa, pgbadger ?).
Mis à jour par Chris Mann il y a plus de 2 ans
PostgreSQL ne supporterait pas le cluster sur DRBD de ses fichiers:
https://stackoverflow.com/questions/22989249/does-postgresql-support-active-active-clustering-with-drbd
Je préconise la prise d'une partition directe vers un disque physique pour les fichiers data de PostgreSQL non pas répliqué sur un serveur et que PostgreSQL soit de cette partition sur un serveur non pas répliqué.
Si je comprends bien, Valise serait entièrement répliquée. Cela, si vrai ferait que Valise ne serait pas approprié pour servir sa propre base PostgreSQL.
Dans ce scénario, je ne vois pas d'autre solution que de mettre la base dès à présent sur une serveur (virtuel OK, mais non pas répliqué, plutôt spécialisé PostgreSQL) avec un système de backup-restore classique par dumps (à voir compatibilité avec Nextcloud, que je peux voir).
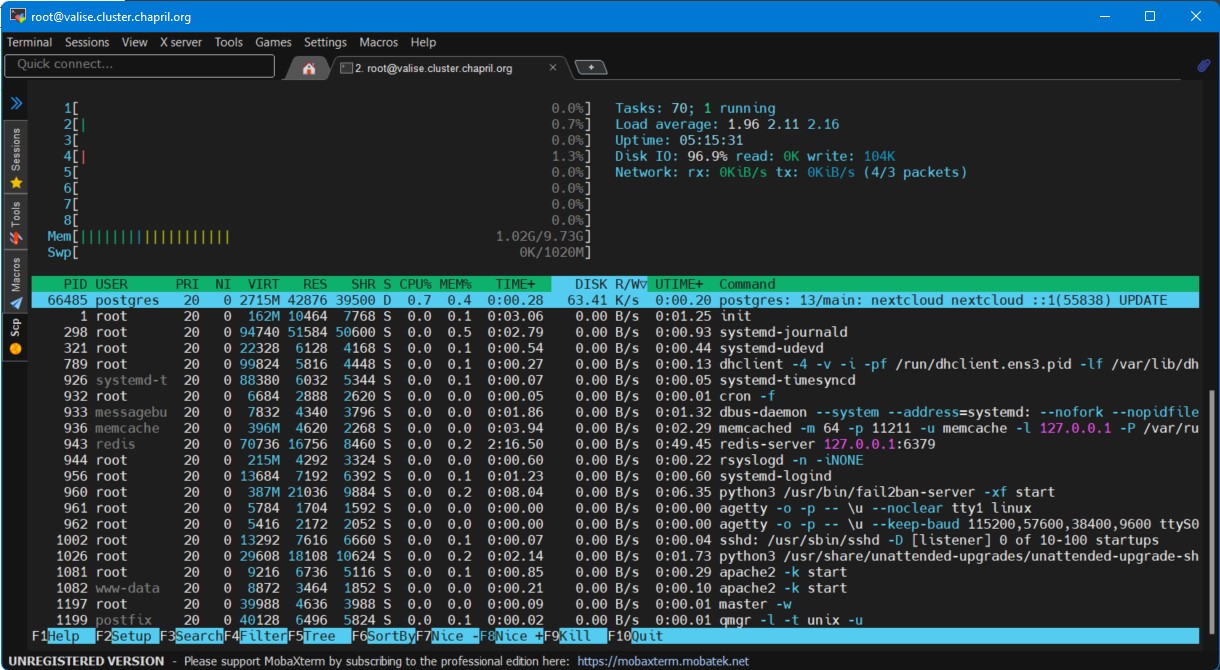
Mis à jour par pitchum . il y a plus de 2 ans
Comme convenu hier soir avec Pilou et Chris, je viens de gonfler encore un peu plus la VM valise : 10Go de RAM et 8CPU.
J'ai adapté la configuration de postgresql pour tenir compte de cet ajout de RAM.
J'ai également augmenté le nombre de workers php-fpm.
À surveiller...
Mis à jour par Pierre-Louis Bonicoli il y a plus de 2 ans
Je propose d'activer le paramètre track_io_timing via le fichier de conf /etc/postgresql/13/main/conf.d/custom-chapril.conf afin de:
collecter des informations de chronométrage sur les lectures et écritures, pour compléter les champs blk_read_time et blk_write_time des vues pg_stat_database et pg_stat_statements (src).
Ce changement nécessite un redémarrage de la base de données.
Voici l'output de la commande pg_test_timing qui permet de vérifier que l'overhead lié à l'activation de ce paramètre n'est pas trop élevé:
# /usr/lib/postgresql/13/bin/pg_test_timing -d 10
Test du coût du chronométrage pour 10 secondes.
Durée par boucle incluant le coût : 23,70 ns
Histogramme des durées de chronométrage
< us % du total nombre
1 97,69648 412162891
2 2,29838 9696444
4 0,00012 526
8 0,00078 3276
16 0,00337 14212
32 0,00074 3115
64 0,00010 405
128 0,00002 89
256 0,00000 20
512 0,00000 15
1024 0,00000 5
2048 0,00000 3
Mis à jour par Chris Mann il y a plus de 2 ans
- Fichier ioplus100netmoins6kbs.jpg ioplus100netmoins6kbs.jpg ajouté
Nous sommes toujours à des attentes d'IO au-dessus de %100 pour des rx et tx net très faibles.
Pour moi, l'expérience est faite. Pas concluante. Voir fichier ci-joint. SAUF, si une choses trèes bien: Postgresql n'est plus victime de meurtre (OOM). Mais sérieusement, Valise est dans les choux sur à cause des IO en lien avec postgres.
Next Step: Il ne reste que la base de données dans une configuration à ne pas génerer autant d'io disque.
Mis à jour par Chris Mann il y a plus de 2 ans
Comme convenu avec @pitchum . et @Pierre-Louis Bonicoli, j'arrête collectd. Les IO sur collectd dépassent postgresql.
Mis à jour par Chris Mann il y a plus de 2 ans
=()=root@valise:~# systemctl stop collectd
=()=root@valise:~# date
mer. 18 mai 2022 19:45:21 CEST
Mis à jour par Chris Mann il y a plus de 2 ans
Pas bcp mieux sans collectd. Voir fichier ci-joint.
J'ai l'impression que sans collectd, c'est sensiblement mieux, mais toujours bien rallenti.
Mis à jour par Chris Mann il y a plus de 2 ans
- Fichier
htp-valise-services-eteints.jpgsupprimé
Mis à jour par Chris Mann il y a plus de 2 ans
Pierre-Louis Bonicoli a écrit :
/etc/postgresql/13/main/conf.d/custom-chapril.conf
Je voudrais bien passer
effective_io_concurrency = 2
à
effective_io_concurrency = 0
(0, au contraire de 1, parait-il interdit toute utilisation de la bibliothèque asynchrone pour de la pure série)
ou peut-être à 10 ou 100 au contraire (peut-être plus d'io cocurrents peuvent faire moins d'attente d'io)
Mis à jour par Chris Mann il y a plus de 2 ans
=()=root@valise:~# ln -s /root/established-timewait.sh /etc/cron.hourly/
=()=root@valise:~# date
mer. 18 mai 2022 23:27:19 CEST
=(^-^)=root@valise:~# cat /root/established-timewait.sh
echo `date -I'minutes'` `netstat |grep "http.*ESTABLISHED"| wc -l`/`netstat |grep "http.*TIME_WAIT"| wc -l` >> /root/established-timewait.log
Mis à jour par Chris Mann il y a plus de 2 ans
=(^-^)=root@valise:~# tail -n2 /etc/cron.d/valisechaprilorg # Statistiques toutes les vignt minutes sur TIME_WAIT */20 * * * * root /root/established-timewait.sh =(^-^)=root@valise:~# cat /root/established-timewait.sh echo `date -I'minutes'` `netstat |grep "http.*ESTABLISHED"| wc -l`/`netstat |grep "http.*TIME_WAIT"| wc -l` >> /root/established-timewait.log =(^-^)=root@valise:~# cat /root/established-timewait.log Time ESTABLISHED/TIME_WAIT 2022-05-18T23:25+02:00 15/165 2022-05-18T23:25+02:00 10/158 2022-05-19T05:51+02:00 1/51 =(^-^)=root@valise:~# date jeu. 19 mai 2022 05:55:17 CEST
Mis à jour par Chris Mann il y a plus de 2 ans
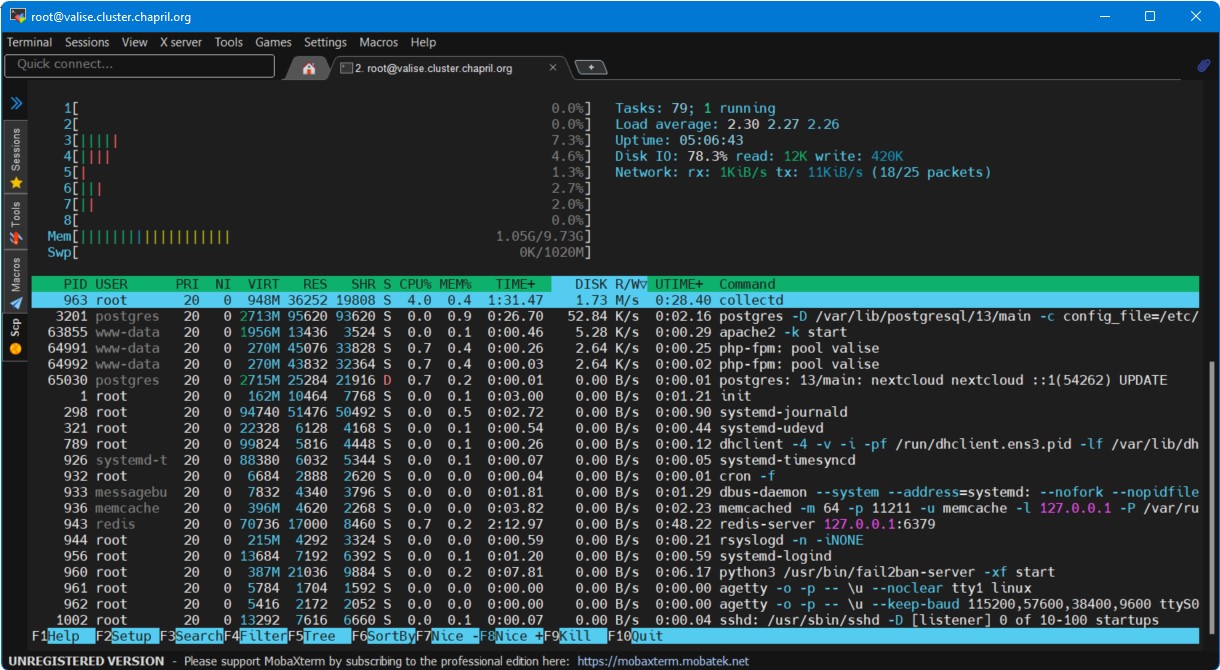
Quand je fais un ps -A, ne note que le PID d'Apache 2 est au-dessus de 100.000.
(Avant le pid de PostgreSQL était plus de 4.080.000)
Cela suggèrerait des rédémarrages fréquents d'apache2 et php-fpm7.4
Mis à jour par pitchum . il y a plus de 2 ans
Chris Mann a écrit :
Quand je fais un ps -A, ne note que le PID d'Apache 2 est au-dessus de 100.000.
Attention, apache tourne avec un process principal qui s'occupe de lancer d'autres process (appelés des workers) en fonction de la demande.
Ces workers sont régulièrement supprimés puis recréés. C'est pas choquant qu'ils aient des PID élevés.
Actuellement le main PID apache est 1081.
=(^-^)=root@valise:~# systemctl status apache2
● apache2.service - The Apache HTTP Server
Loaded: loaded (/lib/systemd/system/apache2.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2022-05-18 14:31:31 CEST; 17h ago
Docs: https://httpd.apache.org/docs/2.4/
Process: 929 ExecStart=/usr/sbin/apachectl start (code=exited, status=0/SUCCESS)
Process: 119891 ExecReload=/usr/sbin/apachectl graceful (code=exited, status=0/SUCCESS)
Main PID: 1081 (apache2)
Tasks: 83 (limit: 11910)
Memory: 97.3M
CPU: 2min 39.933s
CGroup: /system.slice/apache2.service
├─ 1081 /usr/sbin/apache2 -k start
├─119897 /usr/sbin/apache2 -k start
├─120029 /usr/sbin/apache2 -k start
├─139869 /usr/sbin/apache2 -k start
└─140874 /usr/sbin/apache2 -k start
(Avant le pid de PostgreSQL était plus de 4.080.000)
C'est un peu pareil avec postgresql.
=(^-^)=root@valise:~# systemctl status postgresql@13-main
● postgresql@13-main.service - PostgreSQL Cluster 13-main
Loaded: loaded (/lib/systemd/system/postgresql@.service; enabled-runtime; vendor preset: enabled)
Active: active (running) since Wed 2022-05-18 14:39:38 CEST; 17h ago
Process: 3196 ExecStart=/usr/bin/pg_ctlcluster --skip-systemctl-redirect 13-main start (code=exited, status=0/SUCCESS)
Main PID: 3201 (postgres)
Tasks: 26 (limit: 11910)
Memory: 4.1G
CPU: 57min 17.749s
CGroup: /system.slice/system-postgresql.slice/postgresql@13-main.service
├─ 3201 /usr/lib/postgresql/13/bin/postgres -D /var/lib/postgresql/13/main -c config_file=/etc/postgresql/13/main/postgresql.conf
├─ 3223 postgres: 13/main: checkpointer
├─ 3224 postgres: 13/main: background writer
├─ 3225 postgres: 13/main: walwriter
├─ 3226 postgres: 13/main: autovacuum launcher
├─ 3227 postgres: 13/main: stats collector
├─ 3228 postgres: 13/main: logical replication launcher
├─181028 postgres: 13/main: nextcloud nextcloud ::1(60834) INSERT
├─183702 postgres: 13/main: nextcloud nextcloud ::1(35614) INSERT
├─183814 postgres: 13/main: nextcloud nextcloud ::1(35646) UPDATE waiting
├─183815 postgres: 13/main: nextcloud nextcloud ::1(35648) idle
[...]
Cela suggérerait des rédémarrages fréquents d'apache2 et php-fpm7.4
Pareil pour php-fpm : il y a un process principal qui pilote la création/suppression de nombreux process enfants.
=(^-^)=root@valise:~# systemctl status php7.4-fpm
● php7.4-fpm.service - The PHP 7.4 FastCGI Process Manager
Loaded: loaded (/lib/systemd/system/php7.4-fpm.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2022-05-18 15:03:04 CEST; 17h ago
Docs: man:php-fpm7.4(8)
Process: 8255 ExecStartPost=/usr/lib/php/php-fpm-socket-helper install /run/php/php-fpm.sock /etc/php/7.4/fpm/pool.d/www.conf 74 (code=exited, status=0/SUCCESS)
Main PID: 8228 (php-fpm7.4)
Status: "Processes active: 7, idle: 20, Requests: 91756, slow: 0, Traffic: 1.4req/sec"
Tasks: 30 (limit: 11910)
Memory: 1.1G
CPU: 2h 59min 14.873s
CGroup: /system.slice/php7.4-fpm.service
├─ 8228 php-fpm: master process (/etc/php/7.4/fpm/php-fpm.conf)
├─185024 php-fpm: pool valise
├─185034 php-fpm: pool valise
├─185045 php-fpm: pool valise
├─185049 php-fpm: pool valise
├─185067 php-fpm: pool valise
[...]
Bref, la valeur numérique des PID n'est probablement pas un indicateur utile.
Si tu veux savoir depuis quand tourne un service : systemctl status xxxxxxxx
Si tu veux savoir à quels moments ce service a été relancé dernièrement : journalctl -u xxxxxx | grep Starting
Mis à jour par Chris Mann il y a plus de 2 ans
Le PID est anecdotique. Le nombre de TIME_WAIT / Apache est indéniable. Les IO Wait sont aussi indéniables.
Mis à jour par Chris Mann il y a plus de 2 ans
=()=root@valise:~# cat established-timewait.log
Time ESTABLISHED/TIME_WAIT
2022-05-18T23:25+02:00 15/165
2022-05-18T23:25+02:00 10/158
2022-05-19T05:51+02:00 1/51
2022-05-19T06:00+02:00 1/45
2022-05-19T06:20+02:00 2/45
2022-05-19T06:40+02:00 1/71
2022-05-19T07:00+02:00 2/72
2022-05-19T07:20+02:00 2/64
2022-05-19T07:40+02:00 2/75
2022-05-19T08:00+02:00 4/174
2022-05-19T08:09+02:00 5/82
2022-05-19T08:20+02:00 5/90
2022-05-19T08:40+02:00 2/78
2022-05-19T09:00+02:00 1/88
2022-05-19T09:20+02:00 3/126
2022-05-19T09:40+02:00 3/117
=()=root@valise:~# cat established-timewait.sh
echo `date -I'minutes'` `netstat |grep "http.*ESTABLISHED"| wc -l`/`netstat |grep "http.*TIME_WAIT"| wc -l` >> /root/established-timewait.log
Pour référence, sur un autre serveur j'exécute la même commande:
2022-05-19T09:43+02:00 4/0
les connections en TIME_WAIT de netstat sur port 80 par apache montrerait des processus apache qui tournent dans le vide.
Mis à jour par Chris Mann il y a plus de 2 ans
- Fichier established-timewait.log established-timewait.log ajouté
Nous avons beaucoup de connexion TCP en TIME_WAIT sur port HTTP et depuis le processus APACHE. Voir log ci-joint.
Mis à jour par Chris Mann il y a plus de 2 ans
Suite à une discussion avec @Pierre-Louis Bonicoli
Considération de
https://connect.ed-diamond.com/GNU-Linux-Magazine/glmfhs-045/drbd-la-replication-des-blocs-disque
Personnellement, je note cette partie de sa conclusion "Inconvénients majeurs : - pas de granularité sur les objets à répliquer ; - esclaves inaccessibles ; - lenteur à prévoir ;". Les trois points sont problématiques. Si nous avons beaucoup de petits objets dans nos requêtes SQL, peut-être que cela embête DRBD. Si nous n'avons pas l'usage de la fonction native escale SQL, quelles autres fonctions n'existent pas ? Notre problème est précisément les lenteurs. Je note aussi son implémentation sur du HDD et non pas LVM/HDD.
Nous sommes toujours en attente d'un retour de Damien Clochard par rapport. Ma demande de conseil peut être reformulé avec des commentaires éventuels des admins sys.
Nous avions une compréhension différente par rapport à Note 23. Je pense que le disque pour utilisation direct pour un serveur Postgresql peut venir tout de suite. @Pierre-Louis Bonicoli avait écrit long-term. Je ne pense que tout suite pour cette solution pour ensuite voir quoi faire à longue terme. Je pense que les IO nous donneraient assez de temps et d'espace pour analyser justement.
Il y a peut-être une question de susceptibilité.
Il y a peut-être une question d'inconfort avec l'inconnu (surtout en matière de diagnostic).
Mis à jour par Chris Mann il y a plus de 2 ans
Remise en place de CollectD
=()=root@valise:/etc# systemctl start collectd
date
=()=root@valise:/etc# date
ven. 20 mai 2022 16:43:21 CEST
Mis à jour par Chris Mann il y a plus de 2 ans
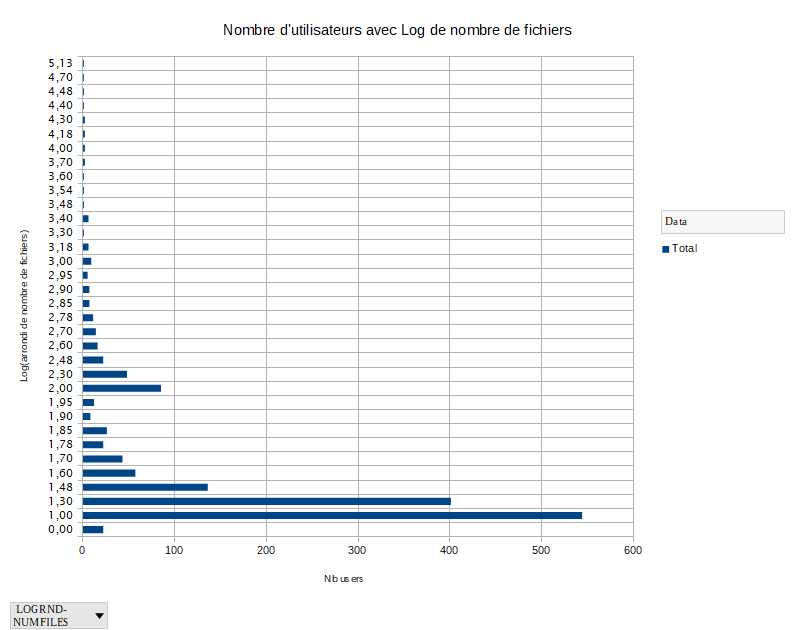
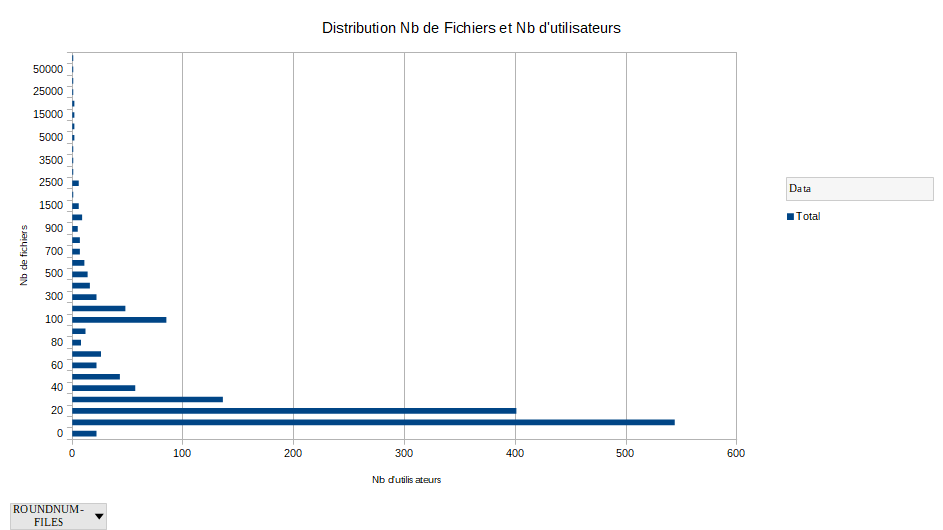
- Fichier _user_files_space.txt _user_files_space.txt ajouté
L'utilisateur 153 a 136.911 fichiers pour 34.212.472 Blocks
Après, dix utilisateurs utilisent entre 10.000 et 60.000 fichiers
Après, les 1513 utilisateurs suivant stockent moins de 10.000 fichiers
Nous pouvons agir sur le compte de l'utilisateur 153 pour améliorer le service pour les autres. Ce montant de fichiers correspond exactement à un déploiement NodeJS.
Voir fichier ci-joint pour les données anonymisées.
NextCloud auriat dû, à mon sens, probablement déporté les traitements nécessaires sur le client de ces 136 mille fichiers.
Mis à jour par Chris Mann il y a plus de 2 ans
Un volume important de fichiers entraîne ce problème.
https://help.nextcloud.com/t/sync-extremely-slow-with-large-number-of-files-on-desktop/102564/4
https://github.com/nextcloud/desktop/issues/691
Voir aussi #5883 et #5884.

Mis à jour par Chris Mann il y a plus de 2 ans
- Fichier graphe-dist-log-nb-files.png ajouté
Mis à jour par Chris Mann il y a plus de 2 ans
- Fichier graphe-dist-log-nb-files.png ajouté
Mis à jour par Chris Mann il y a plus de 2 ans
- Fichier
graphe-dist-log-nb-files.pngsupprimé
Mis à jour par Chris Mann il y a plus de 2 ans
Ce lien décrit parfaitement notre cas de figure:
https://nextcloud.com/blog/nextcloud-sync-2-0-brings-10x-faster-syncing/
Mis à jour par Chris Mann il y a plus de 2 ans
- Fichier graphe-dist-log-nb-files.png graphe-dist-log-nb-files.png ajouté
Je prépare la communication du #5884
https://pad.chapril.org/p/communicationvalise
Il convient aux co-animsys de co-signer si OK @Pierre-Louis Bonicoli
Un premier jet
Mis à jour par Chris Mann il y a plus de 2 ans
Je ne trouve plus les I/O WAIT TIME dans le Grafana dashboards. Est-ce qqpart ?
Mis à jour par Chris Mann il y a plus de 2 ans
- Fichier graphe-dist-nb-files.png graphe-dist-nb-files.png ajouté
- Fichier _user_files_space.ods _user_files_space.ods ajouté
Mis à jour par Chris Mann il y a plus de 2 ans
- Fichier
graphe-dist-log-nb-files.pngsupprimé
Mis à jour par Pierre-Louis Bonicoli il y a plus de 2 ans
Chris Mann a écrit :
Je prépare la communication du #5884
https://pad.chapril.org/p/communicationvalise
Il convient aux co-animsys de co-signer si OK @Pierre-Louis Bonicoli
Je ne comprends pas cette phrase, il me semble qu'elle a le même sens que cette question que tu m'as posé sur IRC sur le salon #april-chapril:
Pilou est-ce que tu signe une communication pour Valise avec moi ? Voici mon démarrage de projet:
https://pad.chapril.org/p/communicationvalise
Si c'est le cas, voici une copie de ma réponse faite sur IRC: c'est pitchum l'animateur du service valise, mes interventions ne l'ont été qu'en tant qu'admin sys, je ne peux donc pas signer en tant que co-animsys du service. Par ailleurs ma compréhension actuelle du service valise ne me permet pas non plus de signer ce projet. Au cas où, cette section s'applique en grande partie pour les communications aux utilisateurs en général.
Mis à jour par Chris Mann il y a plus de 2 ans
Pierre-Louis Bonicoli a écrit :
Je ne comprends pas cette phrase, il me semble qu'elle a le même sens que cette question que tu m'as posé sur IRC sur le salon #april-chapril:
Pilou est-ce que tu signe une communication pour Valise avec moi ? Voici mon démarrage de projet:
https://pad.chapril.org/p/communicationvalise
@Pierre-Louis Bonicoli + @pitchum .: Je vous prie de pardonner mon erreur de vous avoir confondus dans le rôle de co-animateur animsys de Valise. J'ai eu tort. Désolé.
@Pitcum: Peux-tu regarder pour une communication ?
https://pad.chapril.org/p/communicationvalise
Si c'est le cas, voici une copie de ma réponse faite sur IRC: c'est pitchum l'animateur du service valise, mes interventions ne l'ont été qu'en tant qu'admin sys, je ne peux donc pas signer en tant que co-animsys du service.
Effectivement, n'ayant pas compris ton rôle, nous nous sommes mal compris. Voilà le RCA (Root Cause Analysis) de ce bug-là. Encore, désolé.
Par ailleurs ma compréhension actuelle du service valise ne me permet pas non plus de signer ce projet. Au cas où, cette section s'applique en grande partie pour les communications aux utilisateurs en général.
Oui, nous n'avons pas une manière de contacter l'ensemble des utilisateurs d'un service me semble-t-il. Je ne sais pas, du coup, où on mettrait la communication. Bandeau sur l'accueil ? (@pitchum .) D'ailleurs, c'est Didier qui a très gentillement aidé avec la comm.
Mis à jour par Chris Mann il y a plus de 2 ans
pitchum . a écrit :
- remplacement de mpm_prefox+mod_php par mpm_event+fcgid+php-fpm
- utilisation de redis pour : file-locking et memcacheLes perfs sont toujours désastreuses, alors que côté CPU/RAM/Load tout va bien.
Avec apache mod_status on voit que de trop nombreuses requêtes HTTP sont en cours de traitement.
Ça se voit aussi dans les logs apache "/var/log/apache2/valise.chapril.org/valise.chapril.org-access-with-duration.log" + goaccess : le temps de réponse moyen pour /status.php est d'environ 25 secondes.Côté postgresql, je vois souvent des requêtes 'UPDATE "oc_jobs"' qui durent plus de 30 secondes. Je vais creuser de ce côté-là dès que j'ai un moment.
Cette intervention n'aurait pas aidé car le goulot d'étranglement est la base de données probablement à cause des I/O disques (SDD et/ou LVM et/ou DBRD et/ou Hyperviseur en interacton avec PostgreSQL).
https://agir.april.org/issues/5812#note-40
Les requêtes TIME_WAIT en TCP seraient symptôme des frustrations Apache+PHP
Mis à jour par Chris Mann il y a plus de 2 ans
- Lié à Demande #5886: Mettre en Place PostgreSQL Maître/Eslcave / Valises ajouté
Mis à jour par Chris Mann il y a plus de 2 ans
- Lié à Anomalie #5884: Utilisateur 153 sur Valise a 136.000 fichiers ajouté
Mis à jour par Chris Mann il y a plus de 2 ans
- Lié à Demande #5885: Mettre à jour le logiciel NextCloud ajouté
Mis à jour par Chris Mann il y a plus de 2 ans
- Fichier established-timewait.log established-timewait.log ajouté
Mis à jour par Chris Mann il y a plus de 2 ans
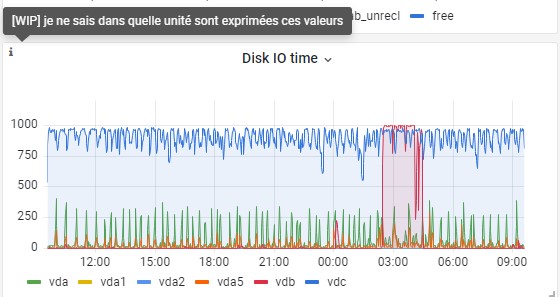
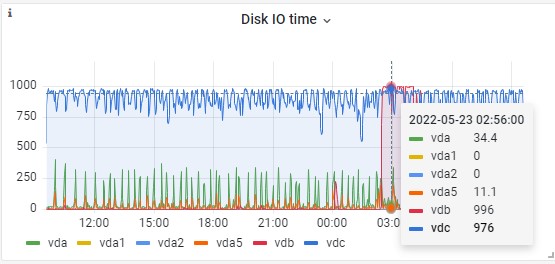
- Fichier graph-2022-05-23-0937-valise-disque-io-time.jpg graph-2022-05-23-0937-valise-disque-io-time.jpg ajouté
- Fichier graph-2022-05-23-093617-valise-disque-io-time.jpg graph-2022-05-23-093617-valise-disque-io-time.jpg ajouté
Regard sur les disques croisé Grafana et console
=(^-^)=root@valise:~# pvscan PV /dev/vdb VG valise-vg-data lvm2 [<500,00 GiB / 0 free] PV /dev/vda5 VG modele-vg lvm2 [<19,76 GiB / <14,34 GiB free] PV /dev/vda1 VG modele-vg lvm2 [240,00 MiB / 240,00 MiB free] PV /dev/vdc VG modele-vg lvm2 [<20,00 GiB / <5,43 GiB free] =(^-^)=root@valise:~# vgscan Found volume group "valise-vg-data" using metadata type lvm2 Found volume group "modele-vg" using metadata type lvm2 =(^-^)=root@valise:~# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert root modele-vg -wi-ao---- <4,07g swap_1 modele-vg -wi-ao---- 1020,00m tmp modele-vg -wi-ao---- 368,00m var modele-vg -wi-ao---- 14,57g nextcloud valise-vg-data -wi-ao---- <500,00g =(^-^)=root@valise:~# mount /dev/mapper/modele--vg-root on / type ext4 (rw,relatime,errors=remount-ro) /dev/mapper/modele--vg-tmp on /tmp type ext4 (rw,relatime) /dev/mapper/modele--vg-var on /var type ext4 (rw,relatime) /dev/mapper/valise--vg--data-nextcloud on /var/www/valise.chapril.org/data type ext4 (rw,nosuid,nodev,noexec,relatime)
Sur graphique ci-joint : VDC constamment près de 1000 et vbd près de 1000 entre 2 et 4 heures de matin. vdc et vdb tt les deux sur modele-vg. Il y aurait une configuration (dont je ne retrouve plus trace) qui orienterait vdc plus vers /var et vda1 et vda5 plus vers /.

D'ailleurs l'unité est milliers de sécondes. "time spent doing I/Os (ms). You can treat this metric as a device load percentage (Value of 1 sec time spent matches 100% of load)."
https://wiki.opnfv.org/display/fastpath/Collectd+Metrics+and+Events

Donc en réponse à la question ci-dessus: l'unité pour Disk I/O Time est milliers de secondes à un load de 1.
Mis à jour par Chris Mann il y a plus de 2 ans
Et voici des stats TIME_WAIT en plus. Les pics sont à 4:20 et 9:00
2022-05-23T00:00+02:00 4/59
2022-05-23T00:20+02:00 1/66
2022-05-23T00:40+02:00 2/73
2022-05-23T01:00+02:00 1/42
2022-05-23T01:20+02:00 1/75
2022-05-23T01:40+02:00 0/32
2022-05-23T02:00+02:00 0/30
2022-05-23T02:20+02:00 2/31
2022-05-23T02:40+02:00 2/32
2022-05-23T03:00+02:00 1/48
2022-05-23T03:20+02:00 1/60
2022-05-23T03:40+02:00 1/44
2022-05-23T04:00+02:00 1/41
2022-05-23T04:20+02:00 1/138
2022-05-23T04:40+02:00 2/34
2022-05-23T05:00+02:00 1/37
2022-05-23T05:20+02:00 1/28
2022-05-23T05:40+02:00 2/33
2022-05-23T06:00+02:00 2/95
2022-05-23T06:20+02:00 1/40
2022-05-23T06:40+02:00 2/29
2022-05-23T07:00+02:00 2/47
2022-05-23T07:20+02:00 1/52
2022-05-23T07:40+02:00 2/58
2022-05-23T08:00+02:00 0/53
2022-05-23T08:20+02:00 28/101
2022-05-23T08:40+02:00 26/78
2022-05-23T09:00+02:00 4/190
2022-05-23T09:20+02:00 21/106
Après le regard sur les disques, je pense que la vue générale sur deux jours raconte une histoire.

Mis à jour par Chris Mann il y a plus de 2 ans
Mis à jour par pitchum . il y a plus de 2 ans
Ce qui pourrait raconter des choses intéressantes, ce serait d'avoir des infos de métrologie concernant postgresql (nombre de connexions actives, nombres de requêtes par seconde, ...).
J'ai entamé un fichier de config /etc/collectd/collectd.conf.d/postgresql.conf mais je n'ai réussi faire fonctionner cette sonde.
Il faudrait que je me repenche là-dessus, mais si quelqu'un s'en occupe avant moi je ne me plaindrais pas :)
Mis à jour par Chris Mann il y a plus de 2 ans
pitchum . a écrit :
Il faudrait que je me repenche là-dessus, mais si quelqu'un s'en occupe avant moi je ne me plaindrais pas :)
Je regarde. Le \ dans le mot de passe m'était traitre.
C'est bon, le sonde marche sur TCP avec un nouvel utilisateur collectd avec droits de lecture sur nextcloud dans PostgreSQL.
● collectd.service - Statistics collection and monitoring daemon
Loaded: loaded (/lib/systemd/system/collectd.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2022-05-24 12:35:24 CEST; 3s ago
Docs: man:collectd(1)
man:collectd.conf(5)
https://collectd.org
Process: 1532033 ExecStartPre=/usr/sbin/collectd -t (code=exited, status=0/SUCCESS)
Main PID: 1532034 (collectd)
Tasks: 12 (limit: 11910)
Memory: 16.3M
CPU: 165ms
CGroup: /system.slice/collectd.service
└─1532034 /usr/sbin/collectd
mai 24 12:35:24 valise.cluster.chapril.org collectd[1532034]: plugin_load: plugin "swap" successfully loaded.
mai 24 12:35:24 valise.cluster.chapril.org collectd[1532034]: plugin_load: plugin "users" successfully loaded.
mai 24 12:35:24 valise.cluster.chapril.org collectd[1532034]: plugin_load: plugin "apache" successfully loaded.
mai 24 12:35:24 valise.cluster.chapril.org collectd[1532034]: plugin_load: plugin "network" successfully loaded.
mai 24 12:35:24 valise.cluster.chapril.org collectd[1532034]: plugin_load: plugin "python" successfully loaded.
mai 24 12:35:24 valise.cluster.chapril.org collectd[1532034]: plugin_load: plugin "postgresql" successfully loaded.
mai 24 12:35:24 valise.cluster.chapril.org collectd[1532034]: Systemd detected, trying to signal readiness.
mai 24 12:35:24 valise.cluster.chapril.org systemd[1]: Started Statistics collection and monitoring daemon.
mai 24 12:35:24 valise.cluster.chapril.org collectd[1532034]: Initialization complete, entering read-loop.
mai 24 12:35:24 valise.cluster.chapril.org collectd[1532034]: Successfully connected to database nextcloud (user collectd) at server localhost:5432 (server version: 13.0.7, protocol version: 3, pid:
Mis à jour par Pierre-Louis Bonicoli il y a plus de 2 ans
- Lié à Demande #5885: Mettre à jour le logiciel NextCloud supprimé
Mis à jour par Pierre-Louis Bonicoli il y a plus de 2 ans
- Lié à Demande #5885: Mettre à jour le logiciel NextCloud ajouté
Mis à jour par pitchum . il y a plus de 2 ans
- Fichier pgbadger_2022-05-26_2146.html pgbadger_2022-05-26_2146.html ajouté
- Statut changé de Nouveau à En cours de traitement
- Priorité changé de Normale à Élevée
C'est cool, maintenant que Chris a réparé le plugin collectd pour postgresql, on pourra envisager de grapher de nouvelles métriques. Je ferai ça au fil de l'eau.
En attendant, j'ai fait tourner pgbadger pendant presque 30h. Ça produit un rapport au format HTML que je ne sais pas encore exploiter. Je le joins au ticket pour que d'autres puissent y jeter un œil également.
Mis à jour par pitchum . il y a plus de 2 ans
Je viens de supprimer le disque expérimental /dev/vdc sur valise. Donc valise est de nouveau dans la configuration nominale : entièrement sur les DRBD de maine et coon, en fichiers qcow2.
Détail des manips.
Sur valise :
pvmove /dev/vdc vgreduce modele-vg /dev/vdc pvremove /dev/vdc
Sur maine :
virsh detach-disk valise vdc --live --config lvremove vg_maine/vm-valise-sys lvremove vg_maine/vm-valise-sys # celui là était déjà inutilisé depuis longtemps
Mis à jour par pitchum . il y a presque 2 ans
- Statut changé de En cours de traitement à Fermé
Tout ça c'est du passé, je ferme le ticket.
Mis à jour par Pierre-Louis Bonicoli il y a plus d'un an
- Version cible changé de Backlog à Sprint 2023 janvier